I'm currently a Research Scientist Intern at Meta on the RL Audio team.
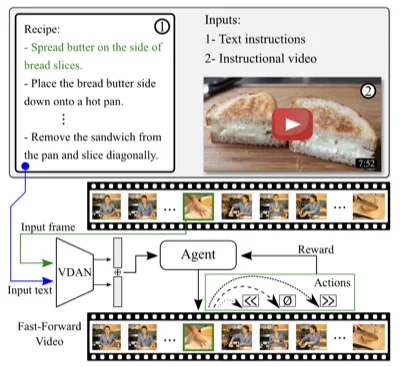
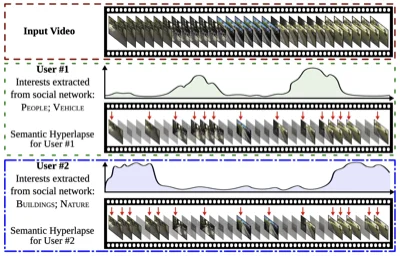
I did my Master's in Computer Science at UFMG under the supervision of Prof. Erickson Nascimento, period in which I was able to collaborate in different research topics such as video summarization and image descriptors.
Email: [first_name]@[last_name].info
News
06.2026Started as a Research Scientist Intern at Meta on the RL Audio team.
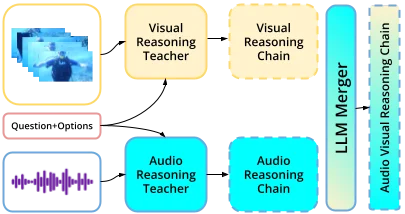
Composes multimodal reasoning traces from single-modality teachers via LLM merging. Achieves +7.8 avg. improvement on audio-visual benchmarks and +6.3 on audio benchmarks.
Soumya Shamarao Jahagirdar*, Edson Araujo*, Anna Kukleva, M. Jehanzeb Mirza, Saurabhchand Bhati, Samuel Thomas, Brian Kingsbury, Rogerio Feris, James R. Glass, Hilde Kuehne
Edson Araujo, Andrew Rouditchenko, Yuan Gong, Saurabhchand Bhati, Samuel Thomas, Brian Kingsbury, Leonid Karlinsky, Rogerio Feris, James R. Glass, Hilde Kuehne
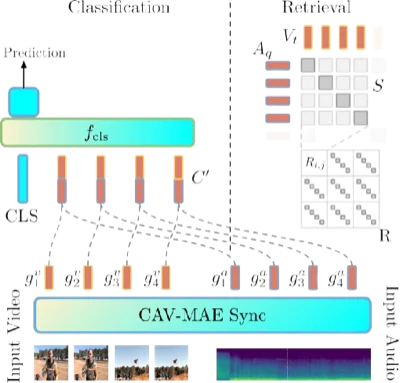
Fine-grained audio-visual alignment using temporal sequences instead of global representations. Outperforms complex architectures on retrieval, classification, and localization.